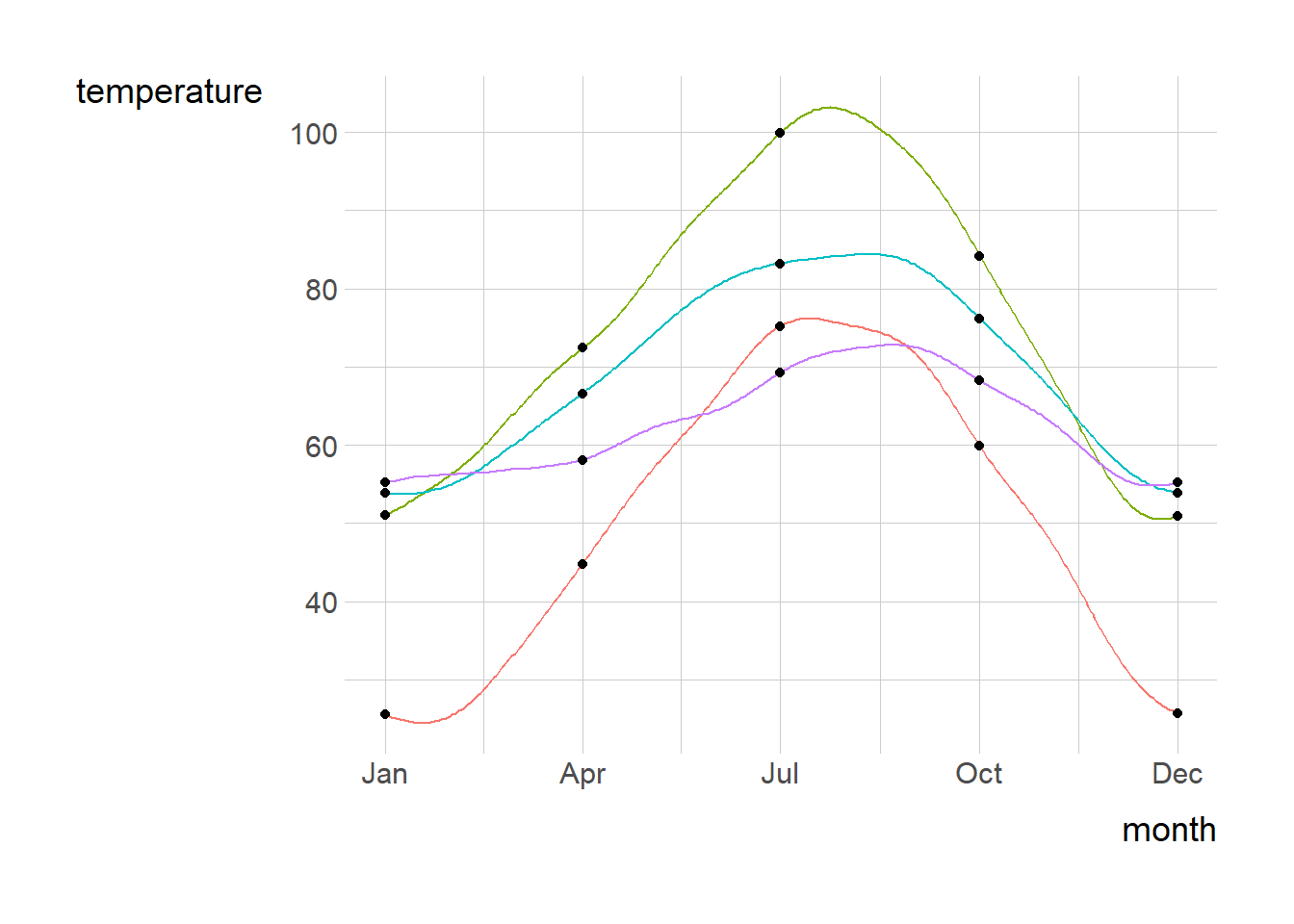
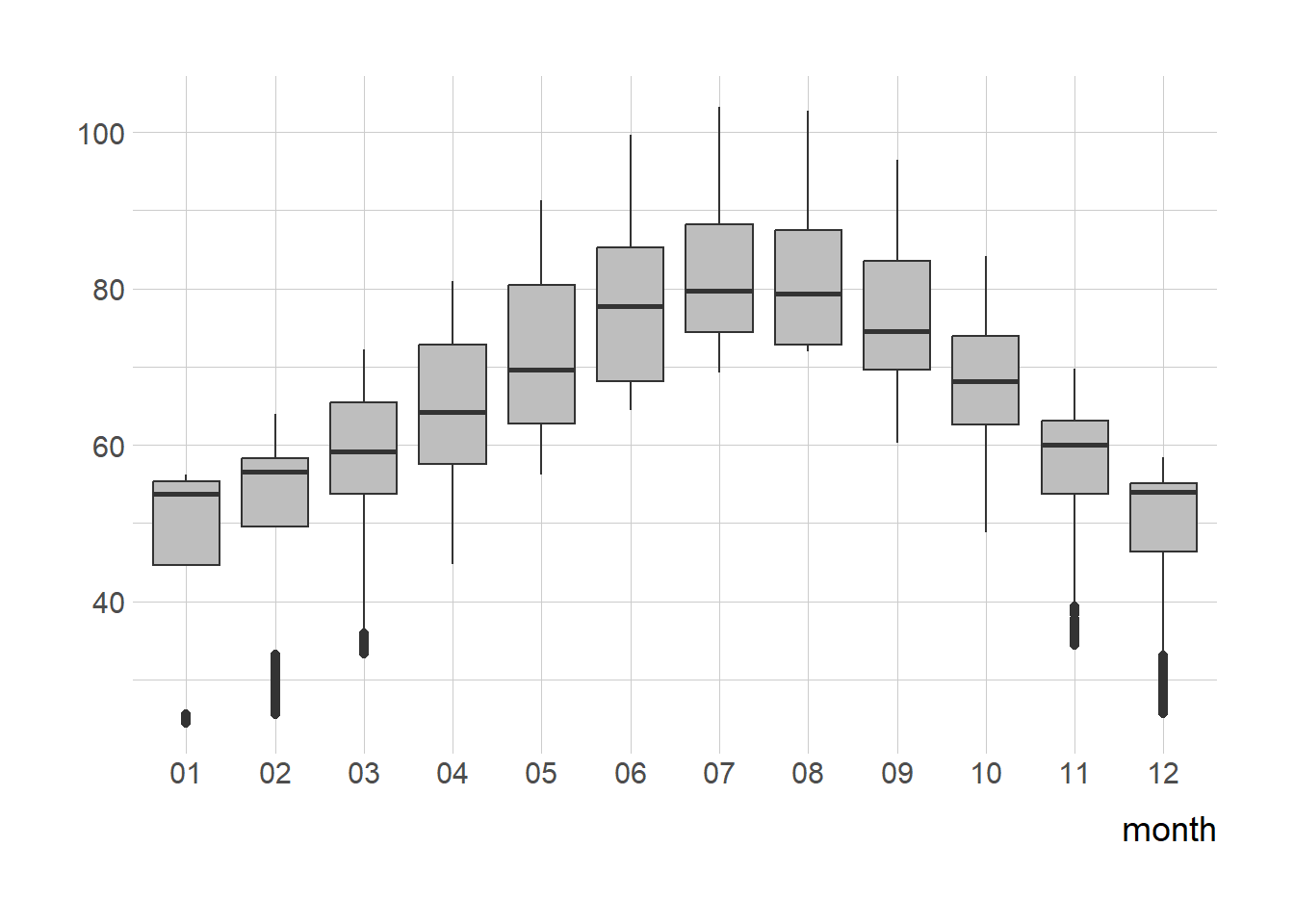
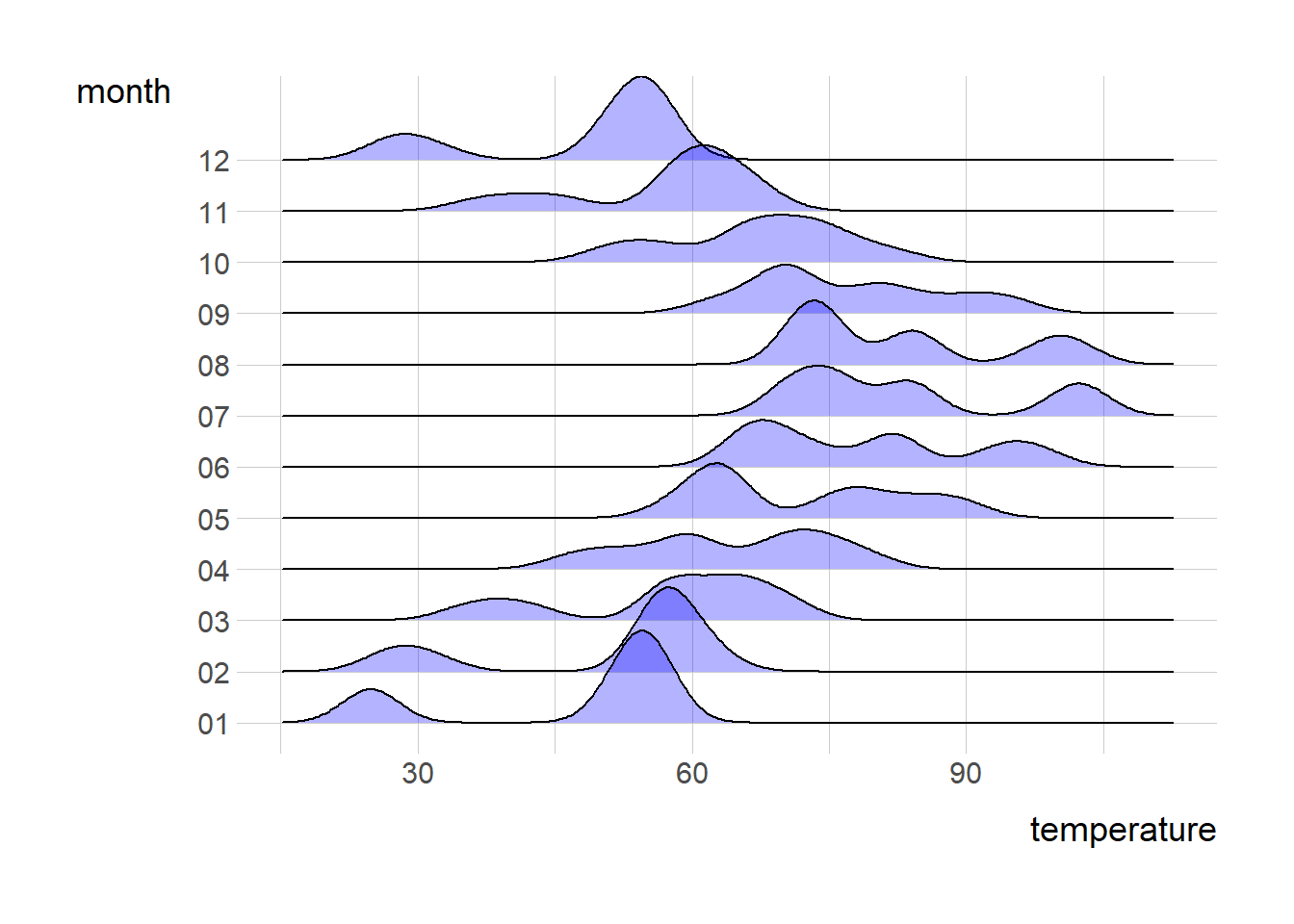
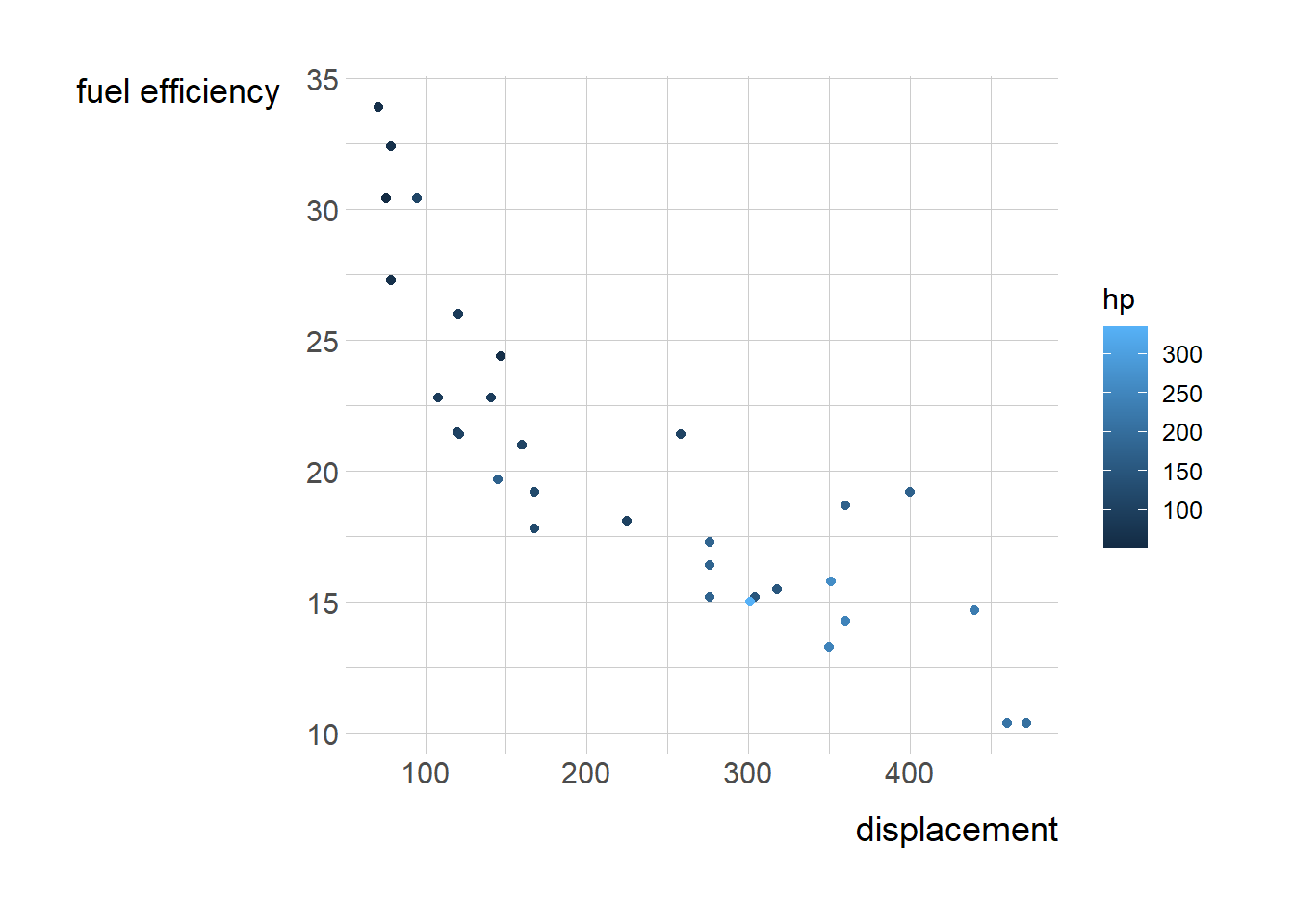
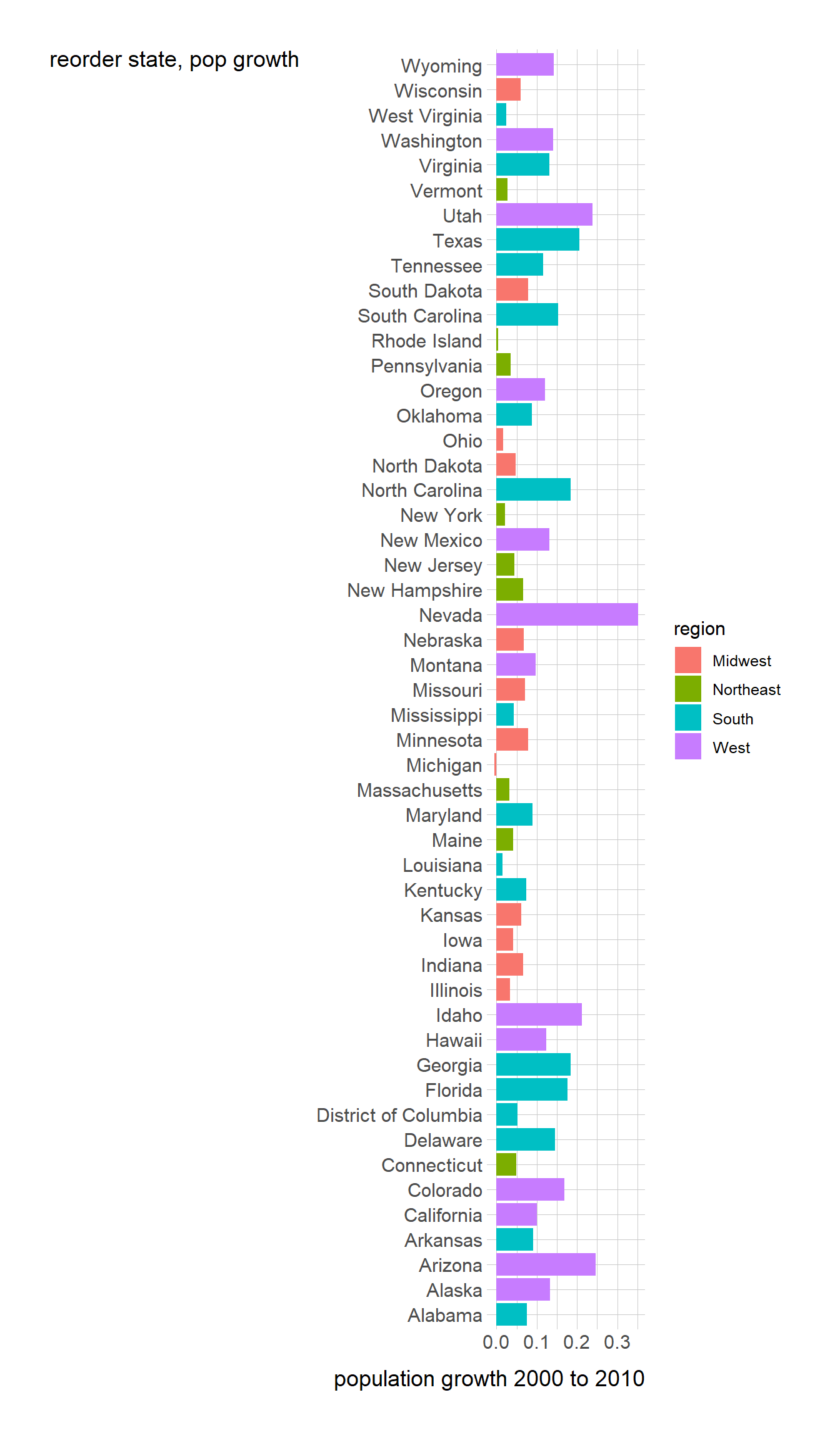
# A tibble: 51 × 7
region division state pop2000 pop2010 popgrowth area
<chr> <chr> <chr> <dbl> <dbl> <dbl> <dbl>
1 Midwest East North Central Michigan 9938444 9883640 -0.00551 56539.
2 Northeast New England Rhode Island 1048319 1052567 0.00405 1034.
3 South West South Central Louisiana 4468976 4533372 0.0144 43204.
4 Midwest East North Central Ohio 11353140 11536504 0.0162 40861.
5 Northeast Middle Atlantic New York 18976457 19378102 0.0212 47126.
6 South South Atlantic West Virginia 1808344 1852994 0.0247 24038.
7 Northeast New England Vermont 608827 625741 0.0278 9217.
8 Northeast New England Massachusetts 6349097 6547629 0.0313 7800.
9 Midwest East North Central Illinois 12419293 12830632 0.0331 55519.
10 Northeast Middle Atlantic Pennsylvania 12281054 12702379 0.0343 44743.
# ℹ 41 more rows
Code
pg<-ggplot(popgrowth_df, aes(state, popgrowth, fill = region)) +geom_bar(stat ="identity", position ="dodge") +coord_flip()pg +labs(y="population growth 2000 to 2010")+labs(x="reorder state, pop growth")